



VIII. Partie VII▲
- Techniques d'analyse syntaxique
- Les requêtes syntaxiques
- Un analyseur pour pascal
- Les erreurs de syntaxe
- Implémentation de Lex.lex_parser
VIII-A. Application à l'analyse syntaxique▲
VIII-A-1. 48. Techniques d'analyse syntaxique▲
On peut distinguer trois familles méthodologiques quand il s'agit de faire l'analyse d'un document texte structuré :
- les outils spécialisés (Lex/Yacc/Bison) utilisent un métalangage pour spécifier la structure du texte, à partir de cette spécification ils génèrent une source qui réalise l'analyse du texte selon cette structure ;
- les parser combinators offrent une collection d'opérations élémentaires d'analyse ainsi que des opérateurs qui permettent de les combiner pour produire des analyseurs plus complexes ;
- la méthode traditionnelle, telle qu'enseignée par Niklaus Wirth, consiste à tout écrire à la main, sans dépendance ni à un outil ni à une bibliothèque.
Le module que nous allons réaliser dans cette partie est une modernisation de la méthode traditionnelle.
Cette méthode suppose d'écrire à la main un analyseur syntaxique de type descendant.
Ce cours ne vous apprendra pas à écrire un analyseur descendant, si vous ne savez pas le faire veuillez vous référer à la littérature classique sur le sujet, par exemple le très classique Compiler Construction de Niklaus Wirth ou bien le cours de Sébastien Doeraene.
VIII-A-2. 49. Les requêtes syntaxiques▲
Le type le plus important exporté par le module Lex est sans aucun doute le type Lex.lex_parser.
Hormis quelques considérations sur l'analyse syntaxique descendante en général, nous allons surtout nous attacher aux spécificités particulières à l'utilisation d'un objet Lex.lex_parser.
Comme vous allez le voir, il s'agit d'une révision de l'analyse syntaxique descendante à la Niklaus Wirth, dont le mérite principal est que la syntaxe y apparaît plus clairement grâce à une formulation plus ramassée.
Pour commencer il n'y a pas d'analyseur lexical au sens habituel.
Par exemple il n'y a pas de mots réservés, mais seulement des mots-clés contextuels.
On ne peut pas définir ses propres unités lexicales, elles sont toutes prédéfinies.
Un élément lexical appartient à l'une de ces sept catégories :
- un word est un mot-clé introduit par le langage, par exemple begin ;
- un name est un identificateur introduit par le programmeur, par exemple push ;
- un mono est un caractère simple, par exemple + ;
- un poly est un caractère multiple, par exemple >= ;
- un string est une valeur chaîne de charactères immédiate, par exemple "hello!" ;
- un char est une valeur caractère immédiate, par exemple 'a' ;
- un int est une valeur entière décimale immédiate non-signée, par exemple 31415.
Après les spécificités lexicales passons maintenant aux spécificités syntaxiques.
Classiquement, en plus de construire un arbre de syntaxe abstraite, un analyseur syntaxique descendant est responsable de trois autres sortes d'opérations élémentaires :
- reconnaître une unité lexicale (souvent à l'aide d'une égalité) ;
- avancer d'une unité lexicale ;
- signaler une erreur syntaxique.
Avec ces quatre tâches différentes, il n'est pas étonnant que le code d'un analyseur descendant apparaisse souvent comme surchargé.
Ce malheureux cumul des mandats est contraire à l'injonction dite de separation of concerns et encourage le recours à des outils spécialisés.
Au contraire de ces outils spécialisés, avec leur notation métalinguistique, le module Lex vous maintient dans le confort du langage OCaml que vous connaissez déjà.
La conception du module Lex est basée sur deux critiques de la méthode traditionnelle :
- les opérations comme reconnaître une unité lexicale ou bien avancer d'une unité lexicale n'ont rien à faire dans un analyseur syntaxique, elles auraient mieux leur place dans un analyseur lexical ;
- les opérations reconnaître-avancer-erreur sont de trop bas niveaux, il faudrait pouvoir les fusionner dans des opérations de plus haut niveau.
Pour remédier à ces deux déficiences, le module Lex propose :
- de redescendre certaines opérations (comme l'égalité) au niveau de l'analyse lexicale ;
- la notion de requête qui combine reconnaître-avancer-erreur en une opération unique.
Désormais, pour effectuer une analyse syntaxique descendante, il vous faudra penser en termes de requêtes demand, granted ou promised qui sont liées aux opérations classiques par l'explication suivante :
- si une requête demand reconnaît alors elle avance sinon elle signale une erreur ;
- si une requête granted reconnaît alors elle avance sinon elle n'avance pas, mais ne signale pas d'erreur ;
- une requête promised reconnaît (ou pas); n'avance jamais; ne signale jamais d'erreur.
Cette explication ne se justifie que par l'expérience de l'analyse descendante, elle n'est pas très intuitive en elle-même.
C'est pourquoi, de façon similaire aux diagrammes syntaxiques, ce formalisme pour les grammaires LL(1) possède sa propre représentation graphique, les ordigrammes syntaxiques, qui va je l'espère vous aider à l'appréhender et à l'utiliser dans vos propres projets.
Les ordigrammes syntaxiques complètent harmonieusement les diagrammes syntaxiques :
- les diagrammes syntaxiques disent à quoi ressemble une phrase, leur sémantique est "déclarative" ;
- les ordigrammes syntaxiques disent comment reconnaître une phrase, leur sémantique est "impérative".
Pour les lire il suffira de savoir que :
- les ordigrammes syntaxiques sont composés d'écluses (ou portes) reliées par des canaux dans lesquels le flux lexical peut s'écouler ;
- le flux lexical entre dans une porte par la gauche ;
- si le flux lexical charrie le motif inscrit sur la porte alors il ressort par la droite, si ce faisant il traverse une puce noire alors l'élément inscrit sur la porte est retiré du flux lexical (la lecture dans le flux lexical avance d'une unité) ;
- sinon le flux lexical est interdit de passage et il poursuit sa course en bas à gauche de la porte ;
- sur une porte les unités lexicales sont marquées en gras tandis que les règles syntaxiques sont marquées en italique ;
- une porte avec deux sorties, une 1re à droite et la 2de à gauche, ne peut pas être gardée par une règle, elle ne peut être gardée que par une unité lexicale
Il en résulte que la grammaire utilise la première unité du flux lexical comme le discriminant d'une phrase, on dit aussi que la grammaire est sous la forme LL(1).
Les requêtes du module Lex sont reliées aux ordigrammes syntaxiques par une correspondance bi-univoque, chaque schéma possédant son équivalent textuel et vice versa :
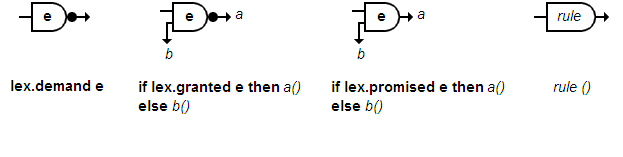
Par exemple l'ordigramme syntaxique d'une séquence :
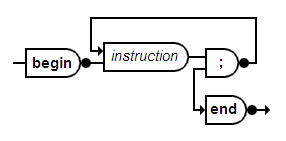
Se traduit textuellement en Caml par la fonction sequence :
let sequence () =
lex.demand_word "begin";
instruction ();
while lex.granted_mono ';' do
instruction ()
done;
lex.demand_word "end"VIII-A-3. 50. Un analyseur pour pascal▲
Dans ce chapitre, afin de se donner une idée plus concrète des facilités et des limites du module Lex, on se propose d'implémenter un analyseur syntaxique descendant pour un langage Turbo Pascal modulaire à peine simplifié (sans extension POO cependant, nous sommes là pour apprendre l'analyse syntaxique, pas pour programmer en Object Pascal).
Pour le besoin du cours cette source TP5.ml est présentée ici en plusieurs morceaux entrecoupés de commentaires. Afin de faciliter vos expérimentations les sources Lex.ml et TP5.ml complètes ainsi que l'exécutable pour Linux et Win32 ont été réunis dans cette archive.
Pour commencer :
- on ouvre le module Lex à l'aide de open Lex ;
- on créer un analyseur lex de type Lex.lex_parser qui lit le flux stdin, pour lire un fichier il suffira de rediriger l'entrée ;
- on créer simple_name (), un analyseur élémentaire qui se contente d'oublier l'identificateur que l'on vient de demander à l'aide de lex.demand_name ().
open Lex;;
let lex = Lex.make stdin in
let rec simple_name () =
ignore(lex.demand_not reserved)Après ce let rec initial les définitions suivantes seront simplement introduites par and. Elles sont donc mutuellement récursives ce qui nous permettra d'utiliser par anticipation des règles de syntaxe pas encore introduites.
Un simple_name est un nom simple, c'est-à-dire non qualifié, comme dans unit test.
Un simple_name est un identificateur, il ne peut pas être un mot réservé.
Nous avons exprimé cette contrainte à l'aide de la requête syntaxique demand_not reserved.
reserved est le nom de notre prédicat qui dit si un mot est réservé ou non.
On peut réserver la liste complète des mots-clés du pascal en les plaçant dans un tableau soumis à un test d'occurrence.
Le module Lex exporte justement une fonction sorted_array_mem, cette fonction réalise un test d'occurrence sur un tableau, nous n'avons pas à chercher plus loin.
and reserved =
Lex.sorted_array_mem
[|
"and";"array";"asm";
"begin";"case";"const";
"div";"do";"downto";"else";"end";
"file";"for";"function";"goto";
"if";"implementation";"in";"interface";
"label";"mod";"nil";"not";"of";"or";"out";
"packed";"procedure";"program";
"record";"repeat";
"set";"shl";"shr";"string";
"then";"to";"type";
"unit";"until";"uses";
"var";"while";"with";"xor";
|]Précisons tout de même que sorted_array_mem fait une recherche dichotomique : elle est efficace, mais elle n'est correcte que sur un tableau trié.
Si par misère notre tableau de mots-clés n'était pas déjà trié, nous pourrions le trier à l'aide de Array.sort.
Bien entendu nous pourrions coder une reconnaissance encore plus efficace des mots réservés, par exemple à l'aide d'un arbre Patricia.
Cette méthode n'aurait rien à envier aux meilleures technologies à base d'automates, toutefois pour avancer plus vite nous laissons ce raffinement à titre d'exercice à la discrétion du lecteur. Et nous progressons promptement dans l'épanchement de notre soif de syntaxe.
Un nom qualifié est un nom suivi par un suffixe comme table dans table^[i].key ou dans table.at(i).
Remarquez que key est un nom et pourrait à son tour être qualifié.
Nous en savons assez pour pouvoir qualifier un nom :
and qualify_name () =
ignore(lex.granted_mono '^');
match lex with
| l when lex.granted_mono '.' ->
simple_name (); qualify_name ()
| l when lex.granted_mono '[' ->
expression ();
lex.demand_mono ']';
qualify_name ()
| l -> arguments ()Il nous reste alors à traiter le dernier cas, où un nom est qualifié par une liste d'arguments réels, comme insert dans insert(key,item).
and arguments () =
if lex.granted_mono '(' then begin
expression ();
while lex.granted_mono ',' do
expression ()
done;
lex.demand_mono ')'; qualify_name ()
endVoilà qui nous amène aux expressions, cela peut paraître intimidant.
Cependant en y regardant de plus près nous avons déjà bien entamé la définition d'une expression.
Plus précisément il ne nous manque que les cas suivants :
- l'expression est une constante entière ou réelle (partie entière plus partie décimale) ;
- l'expression est une constante caractère ;
- l'expression est une constante chaîne de caractères ;
- l'expression est parenthésée ;
- l'expression est préfixée par un opérateur unaire (ou bien - ou bien not) ;
- l'expression est un nom éventuellement qualifié (c'est le cas déjà traité) ;
- l'expression est une opération (ou l'opérateur figure parmi + - * <= >= <> < > = and or xor div mod).
Il n'y a plus qu'à traduire :
and expression () =
( match lex with
| l when lex.promised_int () ->
ignore (lex.demand_int ());
if lex.granted_mono '.' then ignore (lex.demand_int ())
| l when lex.promised_mono '\"' -> ignore (lex.demand_char ())
| l when lex.promised_mono '\'' -> ignore (lex.demand_string ())
| l when lex.granted_mono '(' -> expression (); lex.demand_mono ')'
| l when lex.granted_mono '-' -> expression ()
| l when lex.granted_word "not" -> expression ()
| l -> simple_name (); qualify_name ()
) ;
( match lex with
| l when lex.granted_mono '+' -> expression ()
| l when lex.granted_mono '-' -> expression ()
| l when lex.granted_mono '*' -> expression ()
| l when lex.granted_poly "<=" -> expression ()
| l when lex.granted_poly ">=" -> expression ()
| l when lex.granted_poly "<>" -> expression ()
| l when lex.granted_mono '<' -> expression ()
| l when lex.granted_mono '>' -> expression ()
| l when lex.granted_mono '=' -> expression ()
| l when lex.granted_word "and" -> expression ()
| l when lex.granted_word "or" -> expression ()
| l when lex.granted_word "xor" -> expression ()
| l when lex.granted_word "div" -> expression ()
| l when lex.granted_word "mod" -> expression ()
| l -> ()
)Nous en avons terminé avec les expressions, nous passons aux instructions.
La séquence permet de regrouper une série d'instructions séparées par un point-virgule :
and sequence () =
lex.demand_word "begin";
instruction ();
while lex.granted_mono ';' do
instruction ()
done;
lex.demand_word "end"Finalement une instruction est :
- ou bien une séquence ;
- ou bien une instruction structurée (à choisir parmi if while repeat for with) ;
- ou bien un appel de procédure ;
- ou bien une assignation.
Il n'y a plus qu'à traduire :
and instruction () =
match lex with
| l when lex.promised_word "begin" ->
sequence ();
| l when lex.granted_word "if" ->
expression ();
lex.demand_word "then";
instruction ();
if lex.granted_word "else" then instruction ()
| l when lex.granted_word "while" ->
expression ();
lex.demand_word "do";
instruction ();
| l when lex.granted_word "repeat" ->
instruction ();
while lex.granted_mono ';' do
instruction ()
done;
lex.demand_word "until"; expression ()
| l when lex.granted_word "for" ->
simple_name (); qualify_name ();
lex.demand_poly ":=";
expression ();
if lex.granted_word "to" then ()
else lex.demand_word "downto";
expression ();
lex.demand_word "do";
instruction ();
| l when lex.granted_word "with" ->
simple_name (); qualify_name ();
lex.demand_word "do";
instruction ();
| l ->
simple_name (); qualify_name ();
if lex.granted_poly ":=" then expression ()
else arguments()
Comme vous voyez, ça avance très vite, nous en avons terminé avec les instructions.
Nous passons maintenant aux déclarations de types.
Une caractéristique de pascal, plutôt à l'abandon dans les langages modernes, ce sont ces types anonymes.
Bien sûr il y a les types prédéfinis comme Integer, Longint, Real, Byte, Word, Char, Boolean, Pointer.
Un programmeur pascal peut également définir un nouvel alias de type.
Mais en plus, sans avoir à le nommer, le programmeur pascal peut spécifier :
- un nouveau type chaîne string[max] ;
- un nouveau type fichier file of data_type ;
- un nouveau type tableau array [min..max] of data_type ;
- un nouveau type enregistrement record components end ;
- un nouveau type procedure ou function ;
- un nouveau type pointeur (à l'aide du caractère ^) ;
- un nouveau type énuméré comme (North, East, South, West).
Il n'y a plus qu'à traduire :
and data_type () =
match lex with
| l when lex.granted_word "Integer" -> ()
| l when lex.granted_word "Longint" -> ()
| l when lex.granted_word "Real" -> ()
| l when lex.granted_word "Byte" -> ()
| l when lex.granted_word "Word" -> ()
| l when lex.granted_word "Char" -> ()
| l when lex.granted_word "Boolean" -> ()
| l when lex.granted_word "Pointer" -> ()
| l when lex.granted_word "string" ->
if lex.granted_mono '[' then begin
constant_value ();
lex.demand_mono ']'
end
| l when lex.granted_word "file" ->
lex.demand_word "of";
data_type ()
| l when lex.granted_word "array" ->
lex.demand_mono '[';
constant_value ();
lex.demand_poly "..";
constant_value ();
lex.demand_mono ']';
lex.demand_word "of";
data_type ()
| l when lex.granted_word "record" ->
components ();
lex.demand_word "end"
| l when lex.granted_word "procedure" ->
procedure_type ()
| l when lex.granted_word "function" ->
procedure_type (); lex.demand_mono ':'; data_type ()
| l when lex.granted_mono '^' ->
data_type ()
| l when lex.granted_mono '(' ->
simple_name ();
while lex.granted_mono ',' do
simple_name ()
done;
lex.demand_mono ')'
| l -> simple_name ()Sachant que constant_value(), components () et procedure_type () restent encore à définir.
Une valeur constante est soit un nom (défini à l'aide de const) soit une constante entière :
and constant_value () =
if lex.promised_name () then simple_name ()
else ignore (lex.demand_int ())L'ensemble des composantes d'un enregistrement est une série de déclarations noms:type séparées par des virgules et points-virgules :
and components () =
simple_name ();
while lex.granted_mono ',' do
simple_name ()
done;
lex.demand_mono ':';
data_type ();
if lex.granted_mono ';' then components ()Un type procedure se résume à une (éventuelle) liste d'arguments formels noms:type séparés par des virgules et points-virgules. Ces arguments pourront être annotés const, var, in, out selon la façon dont on peut ou non les modifier.
and procedure_type () =
if lex.granted_mono '(' then
let rec loop () =
( match lex with
| l when lex.granted_word "const" -> ()
| l when lex.granted_word "var" -> ()
| l when lex.granted_word "in" -> ()
| l when lex.granted_word "out" -> ()
| l -> ()
) ;
simple_name ();
while lex.granted_mono ',' do
simple_name ()
done;
lex.demand_mono ':';
data_type ();
if lex.granted_mono ';' then loop ()
in loop (); lex.demand_mono ')'C'est fini pour les types.
Nous avons les expressions, nous avons les instructions, nous avons les types, il nous manque les deux derniers niveaux hiérarchiques supérieurs, à savoir :
- les déclarations (de constantes, de types, de variables globales, de procédures, de fonctions) ;
- les unités et les programmes.
Une simple boucle nous donnera une vue d'ensemble des définitions :
- ou bien une déclaration débute par l'un des mots-clés const type var procedure function ;
- ou bien on quitte la boucle des déclarations.
and declare () =
comments ();
match lex with
| l when lex.granted_word "const" ->
comments (); constant (); declare ()
| l when lex.granted_word "type" ->
comments (); definition (); declare ()
| l when lex.granted_word "var" ->
comments (); components (); declare ()
| l when lex.granted_word "procedure" ->
comments (); procedure (); declare ()
| l when lex.granted_word "function" ->
comments (); typed_procedure (); declare ()
| l -> ()Les déclarations sont souvent un endroit privilégié pour placer des commentaires.
Le module Lex ne gère pas tout seul les commentaires, les commentaires font donc partie de la grammaire.
Nous utiliserons les commentaires d'une ligne tels que Delphi les recommande :
and comments () =
while lex.granted_poly "//" do
lex.demand_line ()
done
La déclaration de constantes réutilise constant_value :
and constant () =
comments ();
simple_name ();
lex.demand_mono '=';
constant_value ();
if lex.granted_mono ';' then constant ()La déclaration de types réutilise data_type :
and definition () =
comments ();
simple_name ();
lex.demand_mono '=';
data_type ();
if lex.granted_mono ';' then definition ()La déclaration de procédures réutilise procedure_type :
and procedure () =
simple_name (); procedure_type ();
lex.demand_mono ';';
procedure_body ()Une fonction est une typed_procedure :
and typed_procedure () =
simple_name (); procedure_type ();
lex.demand_mono ':'; data_type (); lex.demand_mono ';';
procedure_body ()Le corps d'une procédure est :
- ou bien une déclaration avancée forward ;
- ou bien une séquence begin...end éventuellement précédée d'une déclaration locale var (les components d'une procédure).
and procedure_body () =
if not (lex.granted_word "forward") then begin
if lex.granted_word "var" then components ();
sequence ();
end;
lex.demand_mono ';'Un programme débute par program puis un certain nombre de déclarations précèdent une séquence begin...end.
and program () =
lex.demand_word "program";
simple_name ();
lex.demand_mono ';';
comments ();
declare ();
sequence ()Une unité débute par unit.
Puis suivent les sections interface et implementation.
Une unité est éventuellement clôturée par une séquence begin...end.
and modular () =
lex.demand_word "unit";
simple_name ();
lex.demand_mono ';';
comments ();
lex.demand_word "interface";
imports ();
comments ();
declare ();
lex.demand_word "implementation";
imports ();
declare ();
if lex.promised_word "begin" then sequence ()
else lex.demand_word "end"Enfin, une clause d'importation est un mot-clé uses suivi d'une liste de noms d'unités séparés par une virgule :
and imports () =
comments ();
while lex.granted_word "uses" do
comments ();
simple_name ();
while lex.granted_mono ',' do
simple_name ()
done;
lex.demand_mono ';'
done;VIII-A-4. 51. Les erreurs de syntaxe▲
Nous en arrivons au programme principal où il n'est plus question que de :
- discriminer entre unit et program ;
- demander le caractère '.' qui termine tout programme ou unité ;
- traiter les erreurs de syntaxe.
and turbo_pascal_5 () =
try
comments ();
if lex.promised_word "unit" then modular ()
else program ();
if lex.promised_mono '.' then ()
else lex.demand_mono '.'
with
| Lex.Demand_denied(position,demand) ->
Lex.print_position position;
Lex.print_denied demand;
| Lex.Word_reserved(position) ->
Lex.print_position position;
Lex.print_reserved ();
| End_of_file ->
print_endline "unexpected end of text"
in turbo_pascal_5 ()On voit qu'en fait il n'y a que trois erreurs possibles, chacune générant une exception :
- une requête lex.demand_... n'a pas pu être satisfaite et une exception Lex.Demand_denied est levée ;
- une requête lex.demand_not reserved n'a pas pu être satisfaite et une exception Lex.Word_reserved est levée ;
- le texte se termine prématurément et une exception End_of_file est levée.
Lex.print_position, Lex.print_denied et Lex.print_reserved génèrent un rapport d'erreur qui permet à l'utilisateur de localiser l'unité lexicale fautive et de la situer dans son contexte en affichant :
- l'unité lexicale qui était attendue ;
- le numéro de la ligne fautive ;
- le texte de la ligne fautive (le passage incriminé est souligné).
Le traitement spécifique au point qui suit le end final mérite un petit commentaire.
Pour imposer la présence d'un point, il suffit habituellement de la requête :
lex.demand_mono '.';Le problème c'est que si cette requête réussit alors elle va lire une unité lexicale supplémentaire.
Et comme c'est normalement la fin du texte une exception End_of_file va être générée.
Pour éviter ce désagrément, l'idée est de tester la présence du point avec lex.promised et de ne faire appel à lex.demand qu'en cas d'erreur :
if lex.promised_mono '.' then ()
else lex.demand_mono '.'C'est plus alambiqué qu'à l'habitude, mais on obtient le comportement adéquat.
VIII-A-5. 52. Implémentation de Lex.lex_parser▲
L'implémentation du module Lex est très représentative de la flexibilité de l'approche fonctionnelle.
À première vue, avec notre utilisation abondante de la notation pointée, on pourrait penser à quelque classe équipée d'un constructeur make dans le style classique de la programmation orientée objet.
Or il n'en est rien, nous n'avons utilisé que des constructions Caml déjà connues.
La notation pointée n'est due qu'à un type enregistrement dont les composantes sont de type fonctionnel :
type lex_parser =
{
(* demands *)
demand_line : unit -> unit;
demand_word : string -> unit;
demand_mono : char -> unit;
demand_poly : string -> unit;
demand_name : unit -> string;
demand_not : (string -> bool) -> string;
demand_string : unit -> string;
demand_char : unit -> char;
demand_int : unit -> int;
(* promises *)
promised_word : string -> bool;
promised_mono : char -> bool;
promised_name : unit -> bool;
promised_int : unit -> bool;
(* grants *)
granted_word : string -> bool;
granted_mono : char -> bool;
granted_poly : string -> bool;
}Le constructeur make à son tour n'est qu'une fonction ordinaire qui :
- définit des variables locales ;
- définit des fonctions locales manipulant l'état local ;
- utilise ces fonctions locales pour construire un objet de type Lex.lex_parser.
Le squelette de make ressemble à ceci (les passages omis ont été remplacés par ...) :
let make file =
let
(* local variables *)
...
in
(* demands *)
let demand_line () = ...
and demand_word s = ...
and demand_mono c = ...
and demand_poly s = ...
and demand_name () = ...
and demand_not reserved = ...
and demand_string () = ...
and demand_char () = ...
and demand_int () = ...
(* promises *)
and promised_word s = ...
and promised_mono c = ...
and promised_name () = ...
and promised_int () = ...
(* grants *)
and granted_word s = ...
and granted_mono c = ...
and granted_poly s = ...
in
demand_line ();
(* build a lex_parser object *)
{
(* demands *)
demand_line = demand_line;
demand_word = demand_word;
demand_mono = demand_mono;
demand_poly = demand_poly;
demand_name = demand_name;
demand_not = demand_not;
demand_string = demand_string;
demand_char = demand_char;
demand_int = demand_int;
(* promises *)
promised_word = promised_word;
promised_mono = promised_mono;
promised_name = promised_name;
promised_int = promised_int;
(* grants *)
granted_word = granted_word;
granted_mono = granted_mono;
granted_poly = granted_poly;
}