



XI. Partie X▲
65. Les familles de processeurs
66. Architecture processeur et performance
67. Le langage machine
68. Le langage source
69. Quelques compléments sur le langage OCaml
70. La traduction en code machine
71. Le traducteur en action
Pour aller plus loin
XI-A. Application à la génération de code machine▲
XI-A-1. 65. Les familles de processeurs▲
Comme tout composant matériel ou logiciel un microprocesseur comporte une interface et une implémentation :
- l'implémentation est un interpréteur machine pour le jeu d'instructions, son détail diffère d'un modèle à l'autre et n'intéresse pas l'auteur de compilateurs ;
- l'interface est un jeu d'instructions, plus ou moins riche d'un modèle à l'autre il reste néanmoins globalement identique tant qu'on s'en tient à une même famille de microprocesseurs.
On distingue trois grandes architectures de jeu d'instructions :
- les processeurs CISC (Complex Instruction Set Computing) caractérisés par une instruction MOVE, un petit nombre de registres (disons 8 ou 16) et des instructions du genre ADD op,reg où reg est un registre et op un opérande, elle-même étant un registre ou une case mémoire dont l'adresse peut être calculée de façon plus ou moins sophistiquée ;
- les processeurs RISC (Reduced Instruction Set Computing) caractérisés par une paire d'instructions LOAD et STORE, un grand nombre de registres (disons au moins 32), des instructions de longueur fixe et des mnémoniques simples du genre ADD reg1,reg2,reg3 ;
- les processeurs VLIW (Very Long Instruction Word) ou EPIC (Explicitly Parallel Instruction Computing) sont identiques aux RISC, mais caractérisés par des instructions riches capables d'effectuer un plus grand nombre de traitements parallèles, conditionnels ou spéculatifs par cycle d'horloge.
Dans la plupart des architectures, le nombre total d'instructions disponibles est élevé et dépasse souvent la centaine.
Ce nombre n'a en fait que peu d'influence, car bon nombre de ces instructions sont en fait dédiées à des opérations sur des données spécialisées (opérations sur les flottants, les chaînes de bits, les vecteurs), à des manipulations des registres spéciaux et des caches, ainsi qu'à des opérations système (du code en mode superviseur) qui ne concernent pas le code en mode utilisateur.
La richesse du jeu d'instruction n'influe donc pas tellement sur la complexité générale du compilateur.
XI-A-2. 66. Architecture processeur et performance▲
Dans un monde idéal la performance serait uniquement le souci du fondeur et il n'y aurait pas à s'en soucier.
Dans la pratique le jeu d'instructions limite le nombre de variables temporaires (registres) sur lesquelles ont lieu les opérations.
Il incombe donc au compilateur de masquer cette limitation de ressources autant qu'il le peut :
- en effectuant une transformation (register allocation) qui donne l'illusion d'un nombre illimité de variables alors que le nombre de registres est limité ;
- cette transformation va générer des instructions MOVE ou LOAD / STORE qui ne participent à aucun calcul, mais qui agissent comme un cache pour les variables situées en mémoire ;
- avec une transformation naïve, on génère un grand nombre de MOVE ou LOAD / STORE qui peuvent représenter 30 % ou même plus de surcharge en temps d'exécution ;
- une meilleure méthode consiste à modéliser le flot d'exécution pour calculer la durée de vie de chacune des variables (par exemple à l'aide d'une mise sous forme dite SSA pour Single-Static-Assignment) afin de leur assigner un registre pour toute leur durée de vie (au lieu d'une seule opération dans le cas de la transformation naïve) ;
- ce genre d'optimisation est très efficace puisqu'il supprime une grande quantité de MOVE / LOAD / STORE.
Contrairement à ce que l'on pourrait penser la documentation du constructeur de CPU n'est pas l'élément vital dans la génération d'un code performant :
- comme le temps d'exécution d'une instruction sur un processeur moderne dépend du modèle considéré, ainsi que d'un ensemble de conditions dynamiques très difficiles à maîtriser (état du pipeline de décodage, disponibilité du code et des données dans les différents caches, hyper-threading) l'auteur de compilateurs s'intéresse moins à la performance quantitative d'une instruction qu'à sa complexité relative par rapport à une instruction qui lui serait équivalente ;
- il est fondamentalement plus simple de lire un registre que de lire une case mémoire, de faire un décalage à droite que de faire une division par 2, donc dans tous les cas où c'est possible on cherchera à substituer une opération par une autre fondamentalement plus simple ;
- la plupart de ces optimisations sont locales et par conséquent, relativement faciles à implanter ;
- l'optimisation difficile c'est l'optimisation globale, celle dont la portée excède celle d'une expression/instruction dans le langage source ;
- l'optimisation globale la plus payante est celle de register allocation ;
- la bonne nouvelle c'est que cette optimisation est relativement bien portable d'une architecture de CPU à une autre ;
- la mauvaise nouvelle c'est que cette optimisation est relativement difficile à implanter et coûteuse en temps d'exécution par rapport à l'approche naïve.
XI-A-3. 67. Le langage machine▲
Choisir un jeu d'instructions pour un tutoriel de compilation est relativement délicat :
- trop abstrait : le lecteur n'apprendra rien d'immédiatement applicable ;
- trop réaliste : le lecteur n'apprendra rien de général.
Pour ce tutoriel on a fait le choix pragmatique d'une architecture CISC populaire, mais sans rentrer dans le détail de l'encodage des instructions Intel x86, ceci afin de garder une notation de haut niveau tout en restant proche de la machine réelle.
Toujours dans le même but de ne pas surcharger inutilement un code qui se veut essentiellement éducatif, on s'est limité à une seule taille d'opérande à savoir le mot machine soit 32 bits pour ia32 ou 64 bits pour ia64.
En particulier toutes les tailles et tous les déplacements (offset) sont exprimés en nombre de mots machine.
Finalement, pour rester très concret, on donnera une traduction de notre jeu d'instruction abstrait vers deux architectures CISC populaires.
Parmi tous nos registres, nous en réservons trois pour des usages spécifiques :
- un premier servira de pointeur de cadre de pile ;
- un second servira de pointeur d'environnement global ;
- un troisième registre est sans doute déjà réservé comme pointeur de pile.
Les opérandes couvrent l'ensemble des modes d'adressage qui nous seront directement utiles :
- Imm n désigne la valeur constante entière n ;
- Reg n désigne le nième registre ;
- Main n désigne une variable globale située à n mots machines dans l'environnement global ;
- Stack n désigne une variable locale située à n mots machines dans le cadre de pile ;
- Offset(reg,offset) désigne le mot situé à l'adresse reg + offset ;
- ScaleL(reg0,reg1) désigne le mot situé à l'adresse reg0 + reg1 ;
- ScaleD(reg0,reg1) désigne le mot situé à l'adresse reg0 + reg1 * 2.
type asm_op =
| Imm of int (* immediate *)
| Reg of int (* register *)
| Main of int (* global variables *)
| Stack of int (* local variables *)
| Offset of int * int (* record field *)
| ScaleL of int * int (* access to word array *)
| ScaleD of int * int (* access to dword array *)Les étiquettes serviront lors des sauts :
type asm_lab =
{mutable label: int option}Ces conditions serviront lors des sauts conditionnels :
type cond_op =
| Equal | Less | More
| NotEqual | NotLess | NotMoreLes opérateurs binaires, on pourrait en ajouter d'autres cela ne changerait pas notre schéma de traduction :
type bin_op =
| Add | Sub | Mul | Div | Mod | Xor | And | OrFinalement nos mnémoniques utilisent les opérandes et autres éléments précédemment définis :
type asm_instr =
| MoveTo of asm_op * int
| MoveFrom of asm_op * int
| Apply of bin_op * int * asm_op (* binary operation *)
| Addr of int * asm_op (* effective address *)
| Label of asm_lab (* declare label *)
| Branch of asm_lab
| BranchIf of cond_op * asm_lab
| Push of asm_op
| Call of asm_lab
| CallTo of asm_op
| Frame of int (* build stack frame *)
| ReturnPop of int (* return and pop arguments *)
| PushRegs of int
| PopRegs of intOù :
- reg étant un numéro de registre ;
- op étant un opérande ;
- lab étant une étiquette ;
- MoveTo(op,reg) copie le contenu de l'opérande op dans reg ;
- MoveFrom(op,reg) copie reg dans l'opérande op ;
- Apply(⊕,reg,op) applique l'opération reg ⊕ op et place le résultat dans reg ;
- Addr(reg,op) calcule addresse effective op et place le résultat dans reg ;
- Label lab declare l'étiquette lab ;
- Branch lab effectue un saut inconditionnel à l'étiquette lab ;
- BranchIf(cond,asm_lab) effectue un saut conditionnel à l'étiquette lab;S
- Push op empile le contenu de l'opérande op ;
- Call lab effectue un appel de sous-routine à l'étiquette lab ;
- CallTo op effectue un appel de sous-routine à l'addresse effective op ;
- Frame n créer un cadre de pile d'une taille de n mots machine ;
- ReturnPop n retourne à l'appelant et dépile les n paramètres réels ;
- PushRegs n empile tous les registres de 0 à n ;
- PopRegs n dépile tous les registres de n à 0.
Tout en restant abstrait notre assembleur simule assez bien les processeurs CISC réels comme le montre le tableau suivant qui fait le rapprochement avec deux CPU CISC très populaires.
| assembleur abstrait | assembleur Intel 80486 | assembleur Motorola 68020 |
| Imm 0 | 0 | #0 |
| Reg 0 | EAX | D0 |
| Main -2 | [ESI-8] | (-8,A6) |
| Stack -2 | [EBP-8] | (-8,A5) |
| Offset(0,2) | [EAX+8] | (8,A0) |
| ScaleL(0,1) | [EAX+EBX] | (A0,D1.L*4) |
| ScaleD(0,1) | [EAX+EBX*2] | (A0,D1.L*8) |
| MoveTo(op,reg) | MOV reg,op | MOVE.L op,reg |
| MoveFrom(op,reg) | MOV op,reg | MOVE.L reg,op |
| Apply(Add,reg,op) | ADD op,reg | ADD.L op,reg |
| Addr(reg,op) | LEA reg,op | LEA op,reg |
| Branch lab | JMP lab | BRA lab |
| BranchIf(NotEqual,lab) | JNE lab | BNE lab |
| Push op | PUSH op | MOVE.L op,-(A7) |
| Call lab | CALL lab | BSR lab |
| CallTo op | CALL op | JSR op |
| Frame 2 | PUSH EBP MOV ESP,EBP SUB ESP,8 |
LINK A5,#8 |
| ReturnPop 1 | MOV EBP,ESP POP EBP RET 4 |
UNLK A5 RTD #4 |
| PushRegs 2 | PUSH EAX PUSH EBX PUSH ECX |
MOVEM.L D0-D2,-(A7) |
| PopRegs 2 | POP ECX POP EBX POP EAX |
MOVEM.L (A7)+,D0-D2 |
Le fait que notre assembleur abstrait comporte aussi peu d'instructions confirme que les compilateurs, en général, n'utilisent qu'une petite fraction du jeu total d'instruction, ceci pour les raisons déjà évoquées plus haut.
Bien sûr un langage réaliste possède plus de types de données que notre langage jouet qui n'a même pas les nombres flottants. Il y a aussi des opportunités d'exploiter quelques spécificités de l'architecture réelle. Ce ne sont là que quelques extensions et optimisations qui ne changeraient pas le cœur de la traduction qui s'occupe avant tout des expressions simples et des structures de contrôle élémentaires.
XI-A-4. 68. Le langage source▲
On a choisi un langage de programmation impérative structurée de type C/Pascal avec une extension POO.
On en donne ici que l'arbre de syntaxe abstraite issu du front-end et dont on n'a retenu que les informations strictement nécessaires à la traduction dans notre langage machine.
Les variables sont soit simples soit rangées dans un tableau :
type ast_var =
| Var of int (* offset *)
| Array of int * int (* offset, size of item *)À l'aide de ces variables, on peut construire des expressions plus complexes :
- Unit est l'expression vide ;
- Integer n est l'entier constant n ;
- Local n est une variable locale située à n mots dans le cadre de pile ;
- Glocal n est une variable globale située à n mots dans l'environnement global ;
- Member(e,c) est le champ c dans l'enregistrement e ;
- Compare(p,a,b) compare a et b selon le prédicat p ;
- BinaryOp(⊕,a,b) calcule a ⊕ b ;
- ItemAt(a,i) est l'élément d'indice i dans le tableau a ;
- ProcCall(p,a) appelle la procédure p avec la liste d'arguments a ;
- MethodCall(m,o,a) appelle la méthode m de l'objet o avec la liste d'arguments a.
type ast_expr =
| Unit
| Integer of int
| Local of ast_var
| Global of ast_var
| Member of ast_expr * ast_var
| Compare of cond_op * ast_expr * ast_expr
| BinaryOp of bin_op * ast_expr * ast_expr
| ItemAt of ast_expr * ast_expr * int
| ProcCall of ast_proc * ast_expr list
| MethodCall of ast_expr * ast_var * ast_expr listLes instructions sont déclarées d'une façon assez parlante :
and ast_instr =
| Nop
| Block of ast_instr list
| AssignTo of ast_expr * ast_expr
| IfThenElse of ast_expr * ast_instr * ast_instr
| WhileDo of ast_expr * ast_instr
| Loop of ast_instr * asm_lab
| Break of ast_instr
| Return of ast_proc * ast_expr
| Ignore of ast_exprPrécisons tout de même que :
- un Break n'est possible que dans une instruction Loop ;
- Ignore sert avant tout à convertir un appel de procédure/méthode en une instruction.
Enfin, une procédure est un quadruplet formé :
- d'une étiquette (adresse de début du code) ;
- d'une arité (nombre d'arguments) ;
- d'une taille de cadre local (nombre de mots à allouer sur la pile) ;
- d'un corps (liste d'instructions).
and ast_proc =
asm_lab * int * int * ast_instrUne méthode ne sera qu'une variable-procédure c'est-à-dire une procédure située à un certain déplacement.
XI-A-5. 69. Quelques compléments sur le langage OCaml▲
Le code de notre traduction utilise quelques notions nouvelles qui n'ont pas été présentées dans les parties précédentes de ce cours OCaml.
Ce paragraphe ne prétend pas présenter ces notions en profondeur, il se contente de survoler la syntaxe des notions utilisées afin que le code ne fasse pas obstacle à la compréhension.
Tout d'abord :
function pat1 -> val1 | pat2 -> val2 | ... | patn -> valnPermet d'abstraire un filtrage, comme avec :
fun x -> match x with pat1 -> val1 | pat2 -> val2 | ... | patn -> valnMais sans déclarer la variable x, elle reste anonyme.
Ensuite, comme son nom le laisse supposer, OCaml possède une extension POO.
Cette extension orientée objet mériterait à elle seule un cours complet dont les aspects abordés ici ne seraient qu'un maigre aperçu.
Syntaxiquement, une nouvelle classe dotted peut être déclarée ainsi :
class dotted arg1 arg2 =
object
val plus = arg1 + arg2
val mutable minus = arg1 - arg2
method compute = function n -> plus - minus + n
initializer
print_endline "new object created"
endOù :
- arg1 et arg2 sont les arguments du constructeur ;
- le mot-clé val déclare une nouvelle valeur privée locale à l'objet ;
- le mot-clé mutable rend possible l'assignation d'une valeur locale ;
- le mot-clé method déclare une nouvelle valeur publique visible de l'extérieur de l'objet ;
- la section initializer contient du code d'initialisation exécuté uniquement lors de la création de l'objet.
En fait la déclaration d'une classe est une double déclaration :
- elle déclare un nouveau type dotted qui est un type d'objet, c'est-à-dire un type enregistrement ouvert (on dit aussi extensible)
type dotted = <compute: int -> int>- elle déclare une nouvelle fonction new dotted qui renvoie un objet de type dotted
# new dotted;;
- : int -> int -> dotted = <fun>L'envoi de message se fait à l'aide de l'opérateur #.
L'extension POO de OCaml est compatible avec l'inférence de types et respecte la sémantique fonctionnelle du langage.
En particulier lorsqu'un envoi de message demande la méthode d'un certain objet il obtient en résultat une fonction ordinaire.
# (new dotted 1 2)#compute;;
new object created
- : int -> int = <fun>Le constructeur d'une classe est également une fonction ordinaire.
# new dotted;;
- : int -> int -> dotted = <fun>Au même titre que n'importe quelle autre fonction, méthodes et constructeurs peuvent être passés en argument ou être renvoyés comme résultat.
La compatibilité entre deux objets découle de la relation d'inclusion de leurs types d'objet respectifs.
La relation d'inclusion entre types d'objet généralise l'héritage tel qu'il existe dans la plupart des langages POO.
La compatibilité entre types d'objet introduit une nouvelle forme de polymorphisme appelé polymorphisme ad hoc par opposition au polymorphisme paramétrique.
Nous n'en dirons toutefois pas davantage sur cet aspect, car nous n'en aurons pas besoin ici.
Enfin, il existe un constructeur de motif que nous n'avions pas rencontré jusqu'à présent.
Le motif noté pat1 | pat2 est appelé un motif union et filtre toute valeur filtrable par le motif pat1 ou le motif pat2.
Bien sûr pat1 | pat2 doivent être de même type. Ils doivent aussi déclarer le même ensemble de variables.
La fonction offset utilise un motif union pour extraire l'offset d'une variable :
let offset (Var x | Array(x,_)) = xXI-A-6. 70. La traduction en code machine▲
Dans un premier temps il nous faut mettre en place une stratégie d'allocation des registres.
Nous allons utiliser un schéma simple et typique dans les compilateurs CISC :
- un opérateur unaire place le résultat dans le même registre que son argument ;
- un opérateur binaire calcule son argument gauche dans le registre n, son argument droit dans le registre n + 1, puis place le résultat de l'opération dans le registre n.
La figure ci-dessous illustre l'annotation d'un arbre d'expression selon ce schéma d'allocation. Les opérandes (dans les feuilles) et les opérateurs (dans les nœuds) n'y sont pas mentionnés pour mieux faire ressortir les numéros de registre.
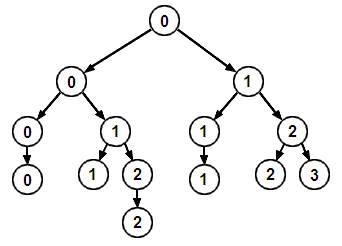
Le nombre de registres strictement nécessaires à l'évaluation d'une expression sans utiliser la pile est égal au nombre de Strahler de l'arbre d'expression à évaluer.
Ce nombre est relativement petit puisqu'il n'augmente que lorsqu'on ajoute un niveau à un arbre complet. C'est ce qui explique que le jeu d'instruction CISC avec son nombre de registres relativement réduit résiste encore face aux nouvelles architectures à plusieurs centaines de registres.
Certaines opérations et, en premier lieu l'appel de fonction sont susceptibles d'écraser un ou plusieurs registres.
Afin que des résultats intermédiaires ne soient pas perdus, ces opérations doivent éventuellement sauver temporairement des registres sur la pile pour ensuite les restaurer en fin de calcul.
Le squelette de notre traducteur est une classe ast_to_asm dont le constructeur attend une liste de procédures qu'il va traduire en code machine. Ces procédures pourront être récursives ou mutuellement récursives, car notre traducteur effectue la mise à jour automatique des sauts en avant.
La classe ast_to_asm commence par quelques formalités pour :
- créer la liste d'instructions dans le champ code ;
- définir label, le numéro de la prochaine déclaration d'étiquette ;
- déclarer deux routines d'émission de code pour les fonctions et méthodes.
Le code qui nous intéresse vraiment prendra place à l'endroit en pointillés.
class ast_to_asm proc_list =
object
val mutable code : asm_instr list = []
val mutable label = 0
method asm_code = List.rev code
initializer
let emit asm = code <- asm::code in
let offset (Var x | Array(x,_)) = x
and emit_call (l,a,f,b) =
emit (Call l)
and emit_callto proc =
match proc with
| Var offset ->
emit (Push (Reg 0));
emit (MoveTo (Offset(0,0),0));
emit (MoveTo (Offset(0,offset),0));
emit (CallTo (Offset(0,0)))
| _ -> assert false
in
...
endLe cœur de notre évaluateur est une fonction eval_val reg expr qui place la valeur de expr dans le registre reg.
Cependant ça n'est pas la totalité de notre évaluateur, en effet, si on plaçait toutes les expressions dans un registre ça ne serait plus du CISC, ça serait du RISC !
Il nous faut en plus un évaluateur auxiliaire capable de placer des expressions dans un opérande au lieu d'un registre.
Il nous faut également un évaluateur auxiliaire capable de calculer l'adresse d'une expression plutôt que sa valeur.
En tout nous avons besoin de pas moins de quatre fonctions auxiliaires :
- eval_arg reg expr place la valeur de expr dans un opérande ;
- eval_addr reg expr place l'adresse de la valeur expr dans reg ;
- eval_scale reg disp place le déplacement disp dans un opérande ;
- eval_push expr place la valeur de expr sur la pile.
let rec eval_arg reg = function
| Integer n -> Imm n
| Local v -> Stack (offset v)
| Global v -> Main (offset v)
| expr -> eval_val reg expr; (Reg reg)
and eval_push expr =
emit (Push (eval_arg 0 expr))
and eval_scale reg = function
| 1 -> ScaleL(reg,reg+1)
| 2 -> ScaleD(reg,reg+1)
| size ->
emit (Apply(Mul,reg+1,Imm size));
ScaleL(reg,reg+1)
and eval_addr reg = function
| Member(record,var) ->
eval_addr reg record;
emit (Addr(reg,Offset(reg,offset var)))
| ItemAt(vector,index,size) ->
eval_addr reg vector;
eval_val (reg+1) index;
emit (Addr(reg,eval_scale reg size))
| expr ->
eval_val reg expr
and eval_val reg = function
...La fonction eval_val applique notre schéma d'allocation de registres sur chacun des noeuds de l'arbre d'expression et émet les instructions appropriées à chacun des cas.
Il n'y a rien de particulier à signaler hormis peut-être l'utilisation du couple d'instructions PushRegs / PopRegs pour conserver les résultats intermédiaires lors des appels de fonctions ou méthodes.
and eval_val reg = function
| Unit ->
()
| Integer n ->
emit (MoveTo(Imm n,reg))
| Local v ->
emit (MoveTo(Stack (offset v),reg))
| Global v ->
emit (MoveTo(Main (offset v),reg))
| Member(record,var) ->
eval_addr reg record;
emit (MoveTo(Offset(reg,offset var),reg))
| Compare(Equal,left,Integer 0) ->
eval_val reg left
| Compare(cond,left,right) ->
eval_val reg left;
let arg = eval_arg (reg+1) right
in emit (Apply(Sub,reg,arg))
| ItemAt(vector,index,size) ->
eval_addr reg vector;
eval_val (reg+1) index;
emit (MoveTo(eval_scale reg size,reg))
| BinaryOp(op,left,right) ->
eval_val reg left;
let arg = eval_arg (reg+1) right;
in emit (Apply(op,reg,arg))
| ProcCall(proc,args) ->
if reg > 0 then emit (PushRegs (reg-1));
List.iter eval_push args;
emit_call proc;
if reg > 0 then begin
emit (MoveTo(Reg 0,reg));
emit (PopRegs (reg-1))
end
| MethodCall(target,proc,args) ->
if reg > 0 then emit (PushRegs (reg-1));
List.iter eval_push args;
eval_val 0 target;
emit_callto proc;
if reg > 0 then begin
emit (MoveTo(Reg 0,reg));
emit (PopRegs (reg-1))
end
in
...À l'aide de cette traduction des expressions, nous sommes maintenant prêts à traduire les instructions.
Encore quelques fonctions utilitaires pour gérer les sauts et mettre à jour les étiquettes :
let forward () =
{label=None}
and emit_label () =
let l = {label=Some label} in
emit (Label l);
label <- label + 1; l
and assign_label l =
let here = Some label in
emit (Label {label=here}); l.label <- here;
label <- label + 1
and branch_to_here from =
emit (Label {label=Some label});
from.label <- Some label;
label <- label + 1
and emit_break = function
| Loop(cmd,ended) -> emit (Branch ended)
| _ -> assert false
and negate = function
| Equal -> NotEqual
| Less -> NotLess
| More -> NotMore
| NotEqual -> Equal
| NotLess -> Less
| NotMore -> More
in
...Évaluer une condition et placer la cible d'une assignation dans un opérande :
let eval_test expr =
eval_val 0 expr;
let l = forward () in
match expr with
| Compare(cond,left,right) ->
emit (BranchIf(negate cond,l)); l
| _ ->
emit (BranchIf(NotEqual,l)); l
and eval_dest reg = function
| Local v -> Stack (offset v)
| Global v -> Main (offset v)
| expr -> eval_addr reg expr; Offset(reg,0)
in
...Et nous pouvons maintenant générer le code pour les instructions :
let rec eval_instr = function
| Nop ->
()
| Block cmds ->
List.iter eval_instr cmds
| AssignTo(source,target) ->
eval_val 0 source;
let dest = eval_dest 1 target in
emit (MoveFrom(dest,0))
| IfThenElse(cond,cmd_t,Nop) ->
let test = eval_test cond in
eval_instr cmd_t;
branch_to_here test
| IfThenElse(cond,cmd_t,cmd_f) ->
let test = eval_test cond in
eval_instr cmd_t;
let done_t = forward () in
emit (Branch done_t);
branch_to_here test;
eval_instr cmd_f;
branch_to_here done_t
| WhileDo(cond,cmd) ->
let start = emit_label () in
let test = eval_test cond in
eval_instr cmd;
emit (Branch start);
branch_to_here test
| Loop(cmd,ended) ->
let start = emit_label () in
eval_instr cmd;
emit (Branch start);
assign_label ended
| Break loop ->
emit_break loop
| Return((l,a,f,b),v) ->
eval_val 0 v;
emit (ReturnPop a)
| Ignore call ->
eval_val 0 call
in
...La génération du code pour les procédures ne consiste plus qu'à déclarer leur étiquette, créer le cadre de pile et traduire leur corps d'instructions :
let eval_proc (l,a,f,b : ast_proc) =
assign_label l; emit (Frame f); eval_instr b
in List.iter eval_proc proc_listXI-A-7. 71. Le traducteur en action▲
Supposons qu'à l'entrée du front-end on ait ce bout de code dans un langage source fictif proche de Pascal/MODULA :
RECORD binary_tree
left: PTR TO binary_tree
right: PTR TO binary_tree
ENDRECORD
PROC height(t:PTR TO binary_tree)
LOCAL l:LONG,r:LONG
IF t = NIL THEN RETURN 0
l := height(t.left)
r := height(t.right)
IF l > r THEN RETURN l+1
RETURN r+1
ENDPROCÀ l'entrée du back-end on aurait alors cet arbre de syntaxe abstraite :
let rec height : ast_proc =
let left = Var 0
and right = Var 1
and zero = Integer 0
and one = Integer 1
and t = Local (Var 2)
and l = Local (Var (-1))
and r = Local (Var (-2))
in
{label=None},
1,
2,
Block
[
IfThenElse(Compare(Equal,t,zero),Return(height,zero),Nop);
AssignTo(ProcCall(height,[Member(t,left)]),l);
AssignTo(ProcCall(height,[Member(t,right)]),r);
IfThenElse
(
Compare(More,l,r),
Block[Return(height,BinaryOp(Add,l,one))],
Nop
);
Return(height,BinaryOp(Add,r,one))
]Il suffit alors d'invoquer notre traducteur :
(new ast_to_asm [height])#asm_code;;Pour obtenir ce code machine :
[Label {label = Some 0}; Frame 2; MoveTo (Stack 2, 0);
BranchIf (NotEqual, {label = Some 1}); MoveTo (Imm 0, 0); ReturnPop 1;
Label {label = Some 1}; MoveTo (Stack 2, 0); MoveTo (Offset (0, 0), 0);
Push (Reg 0); Call {label = Some 0}; MoveFrom (Stack (-1), 0);
MoveTo (Stack 2, 0); MoveTo (Offset (0, 1), 0); Push (Reg 0);
Call {label = Some 0}; MoveFrom (Stack (-2), 0); MoveTo (Stack (-1), 0);
Apply (Sub, 0, Stack (-2)); BranchIf (NotMore, {label = Some 2});
MoveTo (Stack (-1), 0); Apply (Add, 0, Imm 1); ReturnPop 1;
Label {label = Some 2}; MoveTo (Stack (-2), 0); Apply (Add, 0, Imm 1);
ReturnPop 1]Qu'on pourra reformater ainsi pour une meilleure visibilité :
Label 0
Frame 2
MoveTo Stack 2, R0
BranchIf NotEqual, 1
MoveTo Imm 0, R0
ReturnPop 1
Label 1
MoveTo Stack 2, R0
MoveTo [R0], R0
Push R0
Call 0
MoveFrom Stack -1, R0
MoveTo Stack 2, R0
MoveTo [R0 + 1], R0
Push R0
Call 0
MoveFrom Stack -2, R0
MoveTo Stack -1, R0
Apply Sub, R0, Stack -2
BranchIf NotMore, 2
MoveTo Stack -1, R0
Apply Add, R0, Imm 1
ReturnPop 1
Label 2
MoveTo Stack -2, R0
Apply Add, R0, Imm 1
ReturnPop 1À titre de comparaison voici le même programme écrit cette fois manuellement en assembleur 68020 :
STRUCTURE Tree,0
APTR tree_left
APTR tree_right
LABEL tree_sizeof
height_enter:
MOVE.L (4,SP),D0
BEQ.S height_exit0
MOVE.L D0,A0
MOVE.L (tree_left,A0),-(SP)
BSR.S height_enter
MOVE.L (4,SP),A0
MOVE.L D0,-(SP)
MOVE.L (tree_right,A0),-(SP)
BSR.S height_enter
MOVE.L (SP)+,D1
CMP.L D1,D0
BGT.S height_exit1
EXG.L D1,D0
height_exit1:
ADDQ.L #1,D0
height_exit0:
RTD #4La version manuelle est évidemment meilleure :
- elle ne procède pas à la création/destruction d'un cadre de pile ;
- elle n'est pas calquée sur les constructions de la programmation structurée ;
- elle ne contient que 7 instructions MOVE au lieu de 11, car elle alloue les registres beaucoup plus intelligemment.
Le point positif c'est que, malgré sa simplicité, notre générateur ne fait rien de réellement stupide. En particulier on n'a pas besoin d'une passe supplémentaire dans un pipeline qui éliminerait du code inutile. Si on veut améliorer la qualité du code, on peut toujours ajouter des cas au filtrage. Le faire sur l'arbre de syntaxe abstraite est bien plus confortable que de le faire sur une séquence de code.
Par exemple au lieu de l'instruction :
MoveTo Imm 0, R0On peut préférer l'instruction :
Apply Sub, R0, R0Dont l'avantage est de ne pas stocker la constante zéro et donc d'économiser de la place (un mot machine sur CPU Intel).
Pour ça il suffira d'ajouter un cas au filtrage :
and eval_val reg = function
| Integer 0 -> emit (Apply(Sub,reg,(Reg reg)))Évidemment ce serait encore mieux de pouvoir économiser des instructions complètes et on retombe là encore sur le point noir de notre schéma : il génère beaucoup de MOVE.
XI-A-8. Pour aller plus loin▲
Le code que nous avons présenté est assez efficace quant à minimiser le nombre d'instructions PUSH.
Les optimisations que notre traducteur simpliste n'effectue pas se rangent en trois catégories principales :
- minimiser le nombre d'instructions BRANCH à l'aide d'une analyse du CFG (Control Flow Graph) ;
- minimiser le nombre d'instructions MOVE en augmentant la granularité de l'allocation de registre de la taille de l'expression jusqu'à la taille de la fonction, du module ou du programme ;
- retirer le code mort à l'aide d'une analyse du flot de données. C'est particulièrement important dans le cadre du développement modulaire ou POO où l'on thésaurise du code dont seule une petite fraction participe effectivement au programme client.
Des articles Wikipédia donnent des définitions de base pour ces trois domaines :
Dans sa forme la plus simpliste, l'allocation globale de registre se contente de registériser les quelques variables les plus utilisées dans les boucles. C'est une approche simple et utilisée par de nombreux outils populaires gratuits comme LCC.
Pour faire un peu mieux il faut procéder à une mise sous forme de CFG et utiliser une heuristique d'allocation comme linear scan.
Pour une allocation encore plus efficace cumulée avec le retrait du code mort, il faut passer par une représentation intermédiaire dite SSA (Static Single Assignment Form).
Tout cela ce sont des heuristiques, car le problème de l'allocation optimale de registre est NP-complet et même indécidable en présence de boucles.
Ces quelques ressources devraient vous aider à approfondir ces sujets :